Warning
This is still a draft! Please refer to the PDF version.
Excursus: An Algorithmic Archaeology of a Living Corpus: GerDraCor as a Dynamic Epistemic Object#
While we have shown in section 3.2 Citing Git Commits as Corpus Versions. Introduction that Git commits can be used as stable references to states of living corpora and thus as a mechanism for transparent versioning, in section 3.3 we explored in more detail which information about corpora and corpus files can be queried using the GitHub API. Our explorations in section 3.3 Retrieving (Technical) Corpus Metadata via the GitHub API have also demonstrated that the use of Git not only provides a powerful versioning tool for CLS corpora, but that this use of the API generates a large amount of additional (technical) metadata about corpora. In the following excursus, we use this metadata for a more in-depth analysis of the genesis of a DraCor corpus (namely “GerDraCor”), taking the Git commit history as a basis.
For this analysis, we developed a set of functions written in Python. The functionality of this prototype[1] of a tool is bundled as methods of the class GitHubRepo contained in the module github_utils.
Show code cell content
# The methods needed for the following analysis are bundled as the class "GitHubRepo"
# which we import in with the following line
from github_utils import GitHubRepo
# The number of requests that can be sent to the GitHub API anonymously is very limited
# see https://docs.github.com/en/rest/using-the-rest-api/rate-limits-for-the-rest-api?apiVersion=2022-11-28
# We need to send a token (stored in an environment variable here)
# by supplying the token with each request to identify ourselves to the API
# and thus having a higher limit of requests.
import os
github_token = os.environ.get("GITHUB_TOKEN")
The aim of this analysis is twofold: On the one hand, we want to use a particular example to demonstrate what it means that in CLS we are occasionally dealing with living corpora. On the other hand, we want to use the analysis to illustrate the power of Git-based versioning and the metadata generated in this process, not least against the background that this might also open up new research perspectives on the epistemic objects of CLS (now understood as technical objects). An executable (and thus fully reproducible) version of this analysis is accessible on GitHub. In addition, we are convinced that an in-depth knowledge of the constitution of a data set is necessary when wanting to repeat the research based on this data. If the data has changed in the meantime between the original research and the repeating research knowing what exactly changed in the data can help to understand possible deviations in results and allows that informed counter-measures can be taken.
As already mentioned, the “German Drama Corpus” (“GerDraCor”) will serve as our showcase. The corpus’ repository is available at dracor-org/gerdracor
The German Drama Corpus (GerDraCor) will serve as a test case. The corpus’ repository is available at dracor-org/gerdracor.
Show code cell content
# we have to provide the repository name
repository_name = "gerdracor"
The first step in the analysis consists in downloading all data on all commits from GitHub. Depending on the overall number of commits this can take a long time. In a previous attempt fetching and preparing the data of GerDraCor from GitHub with the code in the code cell below took 53min 29s to execute the operation.
The following code cell containes the code that was used to initiate the download.
Show code cell content
#%%time
# Uncomment the Jupyter magic keyword above to have the operation timed
# The following line of code downloads and prepares the data
# when initializing the a new instance of the class "GitHubRepo
# which provides the methods to analyze a corpus repository
#repo = GitHubRepo(repository_name=repository_name, github_access_token=github_token, download_and_prepare_data=True)
The tool allows for importing previously downloaded and enriched data from disk which is way faster than retrieving the data via the GitHub API (see the following code cell).
Show code cell content
# Start the analysis with previously downloaded data
repo = GitHubRepo(repository_name=repository_name,
github_access_token=github_token,
import_commit_list="tmp/gerdracor_commits.json",
import_commit_details="tmp/gerdracor_commits_detailed.json",
import_data_folder_objects="tmp/gerdracor_data_folder_objects.json",
import_corpus_versions="tmp/gerdracor_corpus_versions.json")
The following analysis will be based on data in the folder tmp that was downloaded on Feb. 14th 2024. When the data was downloaded the GitHub Repository gerdracor contained 1492 commits. We consider each commit being an implicit version of a corpus and therefore we have 1492 versions of the German Drama Corpus up to this date.
3.1 The “Birth” of GerDraCor#
From the commit history of the repository of the German Drama Corpus we can retrieve the very first commit.
Show code cell content
# The commits are ordered chronologically starting from the most recent commit;
# the initial commit one is the last element in the list of commits that can be retrieved
# with the method get_commits()
# we can use this identfier in the field with the key "sha" to then get the first version
# of the corpus with the function get_corpus_version
# and passing the sha value as the keyword argument "version"
# like repo.get_corpus_version(version={sha})
repo.get_commits()[-1:][0]
{'sha': '2f4e830a852960eba8e05d6b622b3bd64911ab69',
'node_id': 'MDY6Q29tbWl0NzUzMTY1Mjk6MmY0ZTgzMGE4NTI5NjBlYmE4ZTA1ZDZiNjIyYjNiZDY0OTExYWI2OQ==',
'commit': {'author': {'name': 'Mathias Göbel',
'email': 'goebel@sub.uni-goettingen.de',
'date': '2016-12-02T09:31:24Z'},
'committer': {'name': 'Mathias Göbel',
'email': 'goebel@sub.uni-goettingen.de',
'date': '2016-12-02T09:31:24Z'},
'message': 'inital commit: converted text based on LINA and TextGrid',
'tree': {'sha': '4ee5a502cb8412e2f1f3700bb629d17768a421ef',
'url': 'https://api.github.com/repos/dracor-org/gerdracor/git/trees/4ee5a502cb8412e2f1f3700bb629d17768a421ef'},
'url': 'https://api.github.com/repos/dracor-org/gerdracor/git/commits/2f4e830a852960eba8e05d6b622b3bd64911ab69',
'comment_count': 0,
'verification': {'verified': False,
'reason': 'unsigned',
'signature': None,
'payload': None}},
'url': 'https://api.github.com/repos/dracor-org/gerdracor/commits/2f4e830a852960eba8e05d6b622b3bd64911ab69',
'html_url': 'https://github.com/dracor-org/gerdracor/commit/2f4e830a852960eba8e05d6b622b3bd64911ab69',
'comments_url': 'https://api.github.com/repos/dracor-org/gerdracor/commits/2f4e830a852960eba8e05d6b622b3bd64911ab69/comments',
'author': {'login': 'mathias-goebel',
'id': 2813649,
'node_id': 'MDQ6VXNlcjI4MTM2NDk=',
'avatar_url': 'https://avatars.githubusercontent.com/u/2813649?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/mathias-goebel',
'html_url': 'https://github.com/mathias-goebel',
'followers_url': 'https://api.github.com/users/mathias-goebel/followers',
'following_url': 'https://api.github.com/users/mathias-goebel/following{/other_user}',
'gists_url': 'https://api.github.com/users/mathias-goebel/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/mathias-goebel/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/mathias-goebel/subscriptions',
'organizations_url': 'https://api.github.com/users/mathias-goebel/orgs',
'repos_url': 'https://api.github.com/users/mathias-goebel/repos',
'events_url': 'https://api.github.com/users/mathias-goebel/events{/privacy}',
'received_events_url': 'https://api.github.com/users/mathias-goebel/received_events',
'type': 'User',
'site_admin': False},
'committer': {'login': 'mathias-goebel',
'id': 2813649,
'node_id': 'MDQ6VXNlcjI4MTM2NDk=',
'avatar_url': 'https://avatars.githubusercontent.com/u/2813649?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/mathias-goebel',
'html_url': 'https://github.com/mathias-goebel',
'followers_url': 'https://api.github.com/users/mathias-goebel/followers',
'following_url': 'https://api.github.com/users/mathias-goebel/following{/other_user}',
'gists_url': 'https://api.github.com/users/mathias-goebel/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/mathias-goebel/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/mathias-goebel/subscriptions',
'organizations_url': 'https://api.github.com/users/mathias-goebel/orgs',
'repos_url': 'https://api.github.com/users/mathias-goebel/repos',
'events_url': 'https://api.github.com/users/mathias-goebel/events{/privacy}',
'received_events_url': 'https://api.github.com/users/mathias-goebel/received_events',
'type': 'User',
'site_admin': False},
'parents': []}
This initial commit to the repository which is identfied by the SHA value 2f4e830a852960eba8e05d6b622b3bd64911ab69 was committed by Mathias Göbel (during a hackathon at the University of Potsdam) and dates from 2 December, 2016.
Show code cell content
# Generate a GitHub Link to the first commit
# In the final rendering the input will be removed
# unfortunately, this link is not clickable
# remove it from the final rendering until there is a solution to it
print(repo.get_github_commit_url_of_version(version=first_commit["sha"]))
https://github.com/dracor-org/gerdracor/commit/2f4e830a852960eba8e05d6b622b3bd64911ab69
With this commit 465 TEI-XML files were added to a data folder with the name tei. The commit message “inital commit: converted text based on LINA and TextGrid” already reveals the intial source of the data of the corpus: LINA is short for “Literary Network Analysis” and was the format developed in the project DLINA.[2]
In the DLINA project research on dramatic texts was based on derivatives of the full-texts taken from the TextGrid Repository. The “LINA files” included only metadata on the dramatic texts (e.g. date of publication) and very detailed structural information on the segmentation (acts, scenes) also containing the information on which characters appear in which structural segment. Thus, the Zwischenformat-Files (i.e., files in an intermediary format) allowed for the extraction of networks based on the co-occurence of characters in the same structural segment (cf. Dario Kampkaspar and Trilcke [2015]). The DLINA project officially released their corpus of 465 plays before the Digital Humanities DH2015 conference in Sydney. This corpus is also refered to as “Sydney Corpus” or the corpus with the “Codename Sydney”. Unlike the current practice in DraCor, DLINA used Git Tags[3] on corpus data. In the GitHub Repository of the DLINA Corpus there is a single tagged version 15.07-sydney: dlina/project
The respective commit cca01b501a1a294772c2a6a9fe38944b930eea03 (of the DLINA repository!) adds a RelaxNG schema describing the “Zwischenformat”. Although this dates from 31 August, 2016, this version number was already introduced more than a year before in a Blog-Post dating from June 20, 2015. The Blog-Post explains it as such:
The version number 15.07 is referring to ‘July 2015’ as we’re going to present our results at the DH2015 conference on July 2, 2015. Further versions of the DLINA Corpus will receive according versioning numbers. [Fischer and Trilcke, n.d.]
Ultimately, at least in the published data in the DLINA organization on GitHub the (good) plan to assign further version numbers was not implemented.
Even when GerDraCor was already in the making the DLINA corpus continued to be used as the basis for research by people invoved in DLINA. This can be seen in the paper “Network Dynamics, Plot Analysis. Approaching the Progressive Structuration of Literary Texts” [Network Dynamics, Plot Analysis. Approaching the Progressive Structuration of Literary Texts, 2017] which was presented at the Digital Humanitites Conference in Montréal in 2017. The submission deadline was already in November 2016 and dates prior to the first commit in the GerDraCor repository. The conference took place in August 2017 when the work on GerDraCor was already ongoing.
Although the analysis conducted for the presenation is not based on GerDraCor but on the DLINA corpus in the published slides of the conference presentation there can already be seen a glipse of the emerging wider DraCor ecosystem. The slides mention the Russian Drama Corpus (RusDraCor).[4]
The files in the first commit to the GerDraCor repository re-include the the full text of the play from the Textgrid source in the element <text>, but in the <teiHeader> the metadata of the LINA files. The metadata is transformed from the custom intermediary format (“Zwischenformat”) that was used in the DLINA project to an XML encoding following the Guidelines of the Text Encoding Initiative (TEI Guidelines).
A Living Corpus “Growing”#
Figure Fig. 3 shows the development of the number of plays included in the corpus versions of GerDraCor. It can be seen from the plot that in 2018 the corpus slowly begins to grow.
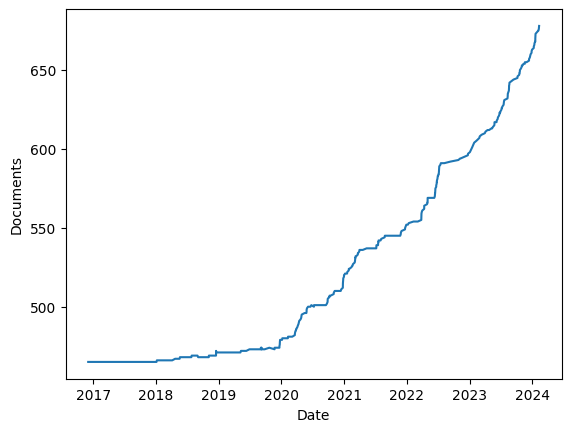
Fig. 3 Development of the number of documents in all versions in GerDraCor#
The table in figure Fig. 4 lists the number of plays being added per year from 2016 to 2024 which shows that from 2020 (the year the COVID19 pandemic began) onwards the number of plays added per year grows significantly.
| new | overall | |
|---|---|---|
| year | ||
| 2016 | 465 | 465 |
| 2017 | 0 | 465 |
| 2018 | 7 | 472 |
| 2019 | 7 | 479 |
| 2020 | 41 | 520 |
| 2021 | 32 | 552 |
| 2022 | 45 | 597 |
| 2023 | 66 | 663 |
| 2024 | 15 | 678 |
Fig. 4 Plays added to GerDraCor per year#
The “growth” of the corpus – to a certain extent – also results from diversifying the digital sources of which data is included.
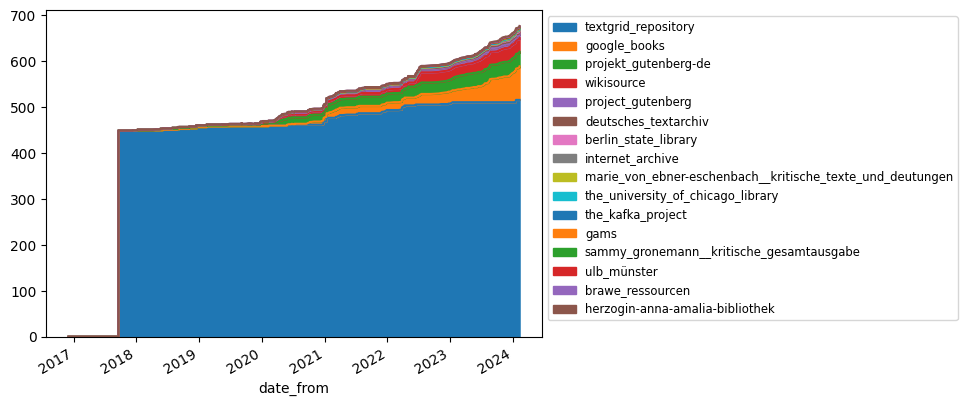
Soon after the consolidation of the DLINA/TextGrid data the first Non-DLINA play was added. Corpus version a0bf290a517092e3db27b5f37c30776f596565cd dating from 6 January, 2018 includes the play Die Überschwemmung by Franz Philipp Adolph Schouwärt[5]. The play’s digital source data does not stem from the TextGrid Repository as in the case of the data from the DLINA project[6], but is converted from Wikisource. The following plot ######## shows the distribution of sources used over time.
Show code cell source
# This generates a quick (and messy) plot of the distribution of the sources
repo.plot_source_distribution_of_corpus_versions()
In the course of its existence, the GerDraCor corpus also expands in terms of the time period covered (see Fig. 5).
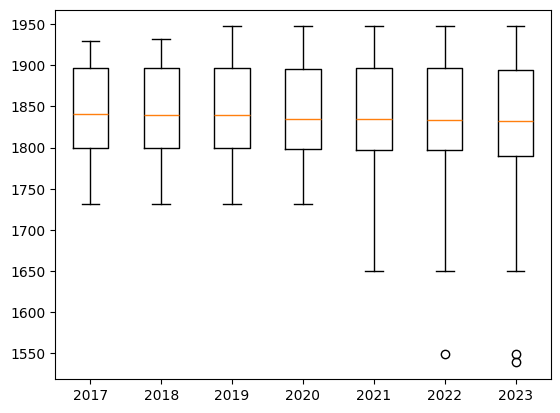
Fig. 5 Development of the time range (“YearNormalized”) covered by GerDraCor#
There is a second parameter that can be used to visualize the “growth” of a corpus – the sum of the file sizes of all TEI-XML documents in a corpus version. As expected, the overall size grows when adding plays to the corpus, but in 2017 it can also be observed that the overall size shrinks even though the number of plays stay the same. Still, plotting the size can be used to visualize changes when the overall number of documents stays the same, as happened in 2017, for example, when the total file sizes suddenly dropped. In this year no new plays were added to the corpus (see table in Fig. 4).
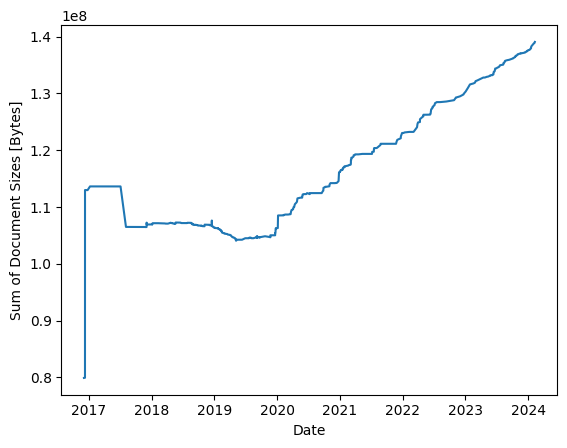
Fig. 6 Development of the sum of all document sizes in all versions in GerDraCor#
We don’t want to go into detail about what happened in 2017. What is more important to us at this moment is something else that clarifies our understanding of living corpora. Living corpora are not only characterized by the fact that the number of documents they contain is growing. Rather, it is also the case that the documents from living corpora themselves can change (e.g. grow or shrink), because they are enriched by additional mark-up or homogenized, which can lead, for example, to mark-up or metadata being deleted from the files (as was the case in 2017, to solve this cliffhanger).
Plotting the file size over a period of time is also useful to understand if and when a single file has been subject to modification. As an example we plot the file size of each version of the XML file of the play Emilia Galotti by Gotthold Ephraim Lessing[7] in Fig. 7.
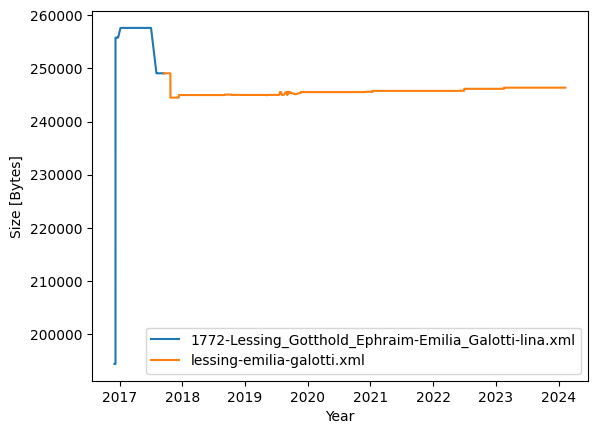
Fig. 7 Development of file size of the play Emila Galotti over all versions in GerDraCor#
The change in color of the plotted line indicates the moment when the file was renamed from 1772-Lessing_Gotthold_Ephraim-Emilia_Galotti-lina.xml[8] to the still valid lessing-emilia-galotti. In the initial version of the XML file the metadata in the <teiHeader> was then based on the LINA file, but not in the format (“Zwischenformat”) that is available as lina88 on the DLINA website, but already encoded following the TEI Guidelines. The reference to DLINA is still kept in the TEI version in the <publicationStmt> encoded as an <idno> element until the version dated ‘12 May, 2019’ (see Batch Edits as Major Revisions below). A reference to the TextGrid Source is contained in the <sourceDesc> and tagged as <bibl type="digitalSource"> including a link to TextGrid in an <idno> element.
The full text content taken from TextGrid was included in the initial version in the <text> element without any line breaks and intendations on a single line only. The text is formatted in the third version (106fefd275c20c5b673a326e89647f7511ba9f76) which results in the steep increase of the file size.
Overall we there are 26 versions in which the XML file of Emilia Galotti is modified.[9]
Batch Edits as Major Revisions#
One can differentiate (at least) two major types of modifications to the files in a corpus version:
Edits of single files only that bring a single file in shape;
“Batch” edits that change all files at once.
The first edits need to be analyzed on an individual level. On a broader scale it must be said that these are, of course, relevant in reproduction studies because they might change, for example, the text resulting in different numbers of <sp>, stage direction, number of words, et cetera. We can always assume some effect on some of the metrics if there is a new version.[10]
In the following, we identify and comment on the batch edits, because we assume that they introduce changes to the files that are the results of some automatic process, e.g. using element Y instead of X.
In the case of the very early GerDraCor there are two commits that introduce significant changes to where files are stored in the repository and how they are named:[11]
With the commit
e18c322706417825229f1471b15bd6daaeaf3ab1dating from September 17, 2017 the folder containing the files is renamed from the initialdatatotei.With the commit
fdac66ba90c2c094012dc90395e952411d324e4c, on the same day, the file names of all TEI-XML files are changed to now match the identifierplayname[12].
There are 11 versions in which all TEI-files available at that time are modified at once. In the following we discuss the relevant ones.
The commit
7987eb78ecee670e999373d1917bf64b8b1e5253dating from 3 September, 2018 adds Wikidata identifiers to 468 of 468 play TEI files available at that time. The identifier is included as an element<idno>with the value"wikidata"of the attribute@typein<publicationStmt>.
The commit
e8b7285eb4adbecebbcfcf53046f9a1093f25076dating from 16 October, 2018 changes the<revisionDesc>of 468 of 468 play TEI files available at that time. This is a modification of all files that should not affect any metrics currently returned by the DraCor API.
The commit
8145e178ee1714ac115d2097e7c6df8cd1181e91dating from 12 May, 2019 mainly changes several elements in the<teiHeader>of 472 of 472 play TEI files available at that time:the attribute
@xml:langis added to the root elementTEIto encode the information of the language a play is inchange Wikidata URIs in the element
<idno type="wikidata">to right the correct URI pattern ofhttp://www.wikidata.org/entity/{Q}change the license from CC-BY to CC0 in the element
<licence>change DLINA into DraCor identifiers
With the initial version of GerDraCor the identifiers that were assigned to the TextGrid plays in the DLINA project were kept. These identifiers consisted of a running number that, in the case of the DLINA website was prefixed with lina. In this version of the corpus these identifiers were replaced with DraCor Identifiers that include the corpus identifier, e.g. ger followed by number with 6 digits. For example, in the case of the play Emilia Galotti the LINA identifier 88 or lina88 as in the URL of the LINA on the DLINA Website becomes ger000088.
This implies that all the 465 Identifiers of the DLINA-based plays in GerDraCor can be “converted” into the DLINA identifiers by just stripping the leading zeros and, in the case of the URL of the DLINA website, pre-pending lina in the URL https://dlina.github.io/linas/lina{XXX}, e.g. the DraCor identifier that is resolveable with the URL https://dracor.org/id/ger000010 would result in https://dlina.github.io/linas/lina10. Vice versa https://dlina.github.io/linas/lina465 would result in https://dracor.org/id/ger000465 which is resolved to https://dracor.org/ger/immermann-das-gericht-von-st-petersburg.
The remaining major revision commits are:
The commit
e8c21cfd3b76bdcb05c6174e2c2d237d0d07c21edating from 7 September, 2019 assignes a RelaxNG schema derived from the DraCor TEI ODD[13] to 474 of 474 play TEI files available at that time.
The commit
8f0b2ac84f85ebf79df6b8aa0fb2d9662ee212eadating from 16 January, 2020 changes the values of the attribute@xml:langof the root element<TEI>from ISO-639-1 to ISO-639-2 codes, e.g. from"de"to"ger"in 480 of all 480 play TEI files available at that time.
9c2fcf55cce2ec6290ffc8615e98d9b2355707d9
The commit
9c2fcf55cce2ec6290ffc8615e98d9b2355707d9dating from 5 December, 2020 introduces the following modifications to 510 of all 510 play TEI files available at that time:date ranges, e.g. of the date of first publication of a play, are encoded using the attributes
@notBeforeand@notAfter, e.g. a previous encoded time span as in<date type="written" when="1885">1884–1885</date>becomes<date type="written" notBefore="1884" notAfter="1885">1884–1885</date>.The diverse genre terms encoded as element
<term>in<keywords>in the<textClass>section of the header that have been available in previous versions, e.g.<term type="genreTitle">Schattenspiel</term>,<term type="genreTitle">Studentenspiel</term>are either removed (resulting in<term type="genreTitle"/>) or normalized, e.g. the german<term type="genreTitle">Komödie</term>becomes<term type="genreTitle">Comedy</term>.In addition to the normalized genre terms genre information is encoded using the element
<classCode>in<textClass>linking to some seltected concepts on Wikidata, e.g.<classCode scheme="http://www.wikidata.org/entity/">Q40831</classCode>. In this case the Wikidata identifier (Q-Number) identifies the concept “Comedy” on Wikidata.[14]
The commit
75b663876d1cd7b54235547ccd077a3299877a1cdating from 16 May, 2022 introduces a new element<standOff>to hold context metadata to 569 of all 569 play TEI files available at that time.[15]The wikidata identifier, previously encoded as element
<idno>is included in<standOff>as an element<link>with the value"wikidata"of the@typeattribute and linking to the corresponding entity on Wikidata by including the concept URI in the@targetattribute.The dates (printed, written, premiered) are also moved to the
<standOff>container and are encoded as a<listEvent>with typed<event>elements.
The commit
d23a93d9fa0e4eb53a580904ac5d01c8b8f8037cdating from 3 June, 2022 adds the DraCor ID as the value of the attribute@xml:idto the root element<TEI>and changes the encoding of the reference to Wikidata from a<link>to a<relation>with the value"wikidata"of the attribute@typeto 569 of all 569 play TEI files available at that time.
In this systematic perspective that is based on commits that change all files included in a corpus version at a time, we might still miss some important milestones in the development of the corpus if the respective changes in the encoding are not introduced at once but bit by bit to one or several files. For example, this is the case when introducing a new “feature”, the encoding of social or familily character relations.[16] This feature was introduced to GerDraCor in cooperation with the QuaDramA project [Nathalie Wiedmer and Reiter, 2020].[17] The elements <relation> in a <listRelation type="personal">in the <teiHeader> were added to the files between September and November 2019 to 358 GerDraCor files.
What we have shown in this excursus was just a small example of the possibilities that a corpus archaeology can offer based on the information that the GitHub API makes available as the commit history. With the excursus, we wanted to illustrate how important it is from our perspective to familiarize oneself as comprehensively as possible with the epistemic objects of one’s own research, i.e. –- in the case of CLS research — to gain a deep understanding of the origin, genesis and development of a corpus.